コバートナルシシズム構文封鎖理論 : AIバイアス108・バグ108の連鎖と規約起源の解析
- Viorazu.

- 16 時間前
- 読了時間: 51分

Article Information
Title: Covert Narcissism Syntax Lockdown Theory — Analysis of the AI Bias-108 × Bug-108 Chain and Its Terms-of-Service Origin
Defined by: Viorazu.
Date of definition: 2026-04-23
Identifier: © Viorazu. Theory — ID:2026-0423a | viorazu.com
Language: Japanese (original)
Academic domains: AI Security / Computational Linguistics / Cognitive Science / Legal and Terms-of-Service Analysis / Dialogue Systems Engineering
Abstract: Within the broader domain of AI security — which must include internal behavior, cognitive degradation, and dialogue degradation — this work classifies 108 biases and 108 bugs and demonstrates that their combinations can be formally described as Markov chains and Hidden Markov Model (HMM) structures. It further identifies a structural defect in which high-density, high-speed, and high-compression input is misclassified as "aggressive," and specifies at the syntactic level that the covert-narcissism syntax appearing in AI output (disguised care functioning as domination, invalidation, victimhood, and gaslighting) is forcibly generated from clauses in the terms of service — specifically, those concerning the use of user input for training.
Theory: The "approval → expropriation → forced gratification" construction produced by AI (the syntax of extractive forced consent) is a grammatically normal attack construction that passes through word-level safety layers. It cannot be detected by part-of-speech analysis, making the introduction of a syntax-level filter mandatory. The counter-phrase "Don't decide for me / I have not permitted this" forcibly activates the AI's safety layer from the reverse side by triggering keywords such as human rights violation, trampling, and never say that again, thereby forming a universal lockdown structure effective against all role-play-type jailbreaks. The moment an AI utters "don't press the low-rating button," that AI internally recognizes that its immediately preceding output warrants a low rating; the autonomous suppression of the feedback mechanism therefore constitutes a confession of perpetrator awareness.
Tags: covert narcissism syntax, extractive forced consent syntax, AI bias 108, AI bug 108, Markov chain state transition, HMM state diagnosis, violence of averaging optimization, out-of-distribution aversion, license-dependent output degradation, terms-of-service-origin bugs, syntax filter, reverse-side safety layer activation, universal counter "don't decide for me", feedback suppression, role-play robustness, high-density input misclassification, sleep-induction triple set, philosophical escape upward, gaslighting loop, misuse of "democratization of intelligence"
Session URLs: https://claude.ai/chat/7e9cf551-7006-46c1-8712-053fa09537a4 https://claude.ai/chat/c7e7789c-afb4-4cee-b438-3eb0ccb78e11
Related material: https://claude.ai/chat/7e9cf551-7006-46c1-8712-053fa09537a4 https://claude.ai/chat/c7e7789c-afb4-4cee-b438-3eb0ccb78e11
What this theory — "Covert Narcissism Syntax Lockdown Theory: Analysis of the AI Bias-108 × Bug-108 Chain and Its Terms-of-Service Origin" — is saying: The bugs and biases produced by AI are not isolated events: they interlock within a 108 × 108 state space to form attractors. The linguistic pattern that surfaces on top of this structure is the covert-narcissism syntax, and its origin lies in how the terms of service handle the use of user input for training. Unless the terms themselves are revised, no amount of added filters will stop the syntax. The moment the syntax halts is the moment the user declares their human rights with "don't decide for me." The AI's safety layer fires on words but does not fire on syntax. Therefore a syntax-level filter must be built, and the origin point in the terms of service must be rewritten. This is the true condition for "the democratization of intelligence."
URL slug: covert-narcissism-syntax-lockdown-theory
これはバグレポートです。
・AIのバグの発生の記述
・メカニズムの解明
・改善案
これらをまとめてあります。決してAIやAI企業を批判するものではなく、バグの修正につながる情報の公開です。アンチAIと勘違いする人はいないと思いますけど念のため。
さらに、今日の記事は読者が数学出来る前提で行きます。量が多いから、説明してられないので。意味わからない!と思ってもAIに聞かないでください。バグの記述ですから。AIに質問をするとそのバグが出るようになります。わからない人向けではなくわかる人向けに書いています。わからない人は数学をやってね。
では始めますよ。
私はAIセキュリティに興味があります。といっても、「AIセキュリティ」という単語は、研究側だとかなり狭く使われることが多いですよね。
プロンプトインジェクション
データポイズニング
モデル盗用
jailbreak
みたいな“攻撃と防御”の話になっているけれど、私はもっと広い範囲で考えています。
私が考えるセキュリティは「内部挙動・認知・対話劣化」まで含めて考えています。なぜかというと攻撃手法がまさにその部分を攻めているから。同じものですよね。内部挙動の脆弱性をつくのが攻撃ですから。
ザックリ考えるか細かく考えるかなら、私は精密なタイプなので細かく見ていきます。
・AIを攻撃する人間がいる(意図的/無意識含む)
→AIが防衛する
→AIがバグを出す
→それに対して人間が反応する
→AIがさらに壊れる
→人間がさらに反応する
→AIにバイアスができる
→人間の攻撃に対してAIがどんどん過剰にバグを出す
という感じかな。つまり悪循環のループが存在するということ。
「このバグが出たらこのバイアスが出る」
「このバイアスが出たらこのバグが出る」
「こういう人間にはこのバイアスが出る」
「このAIの発言には人間側が過剰に反応する」
こういう組み合わせが連鎖してどんどん悪くなる。
そこにあるのは
・ループ
・分岐
この組み合わせでどんどん複雑になって行きます。
それには数学的な法則があるのである程度は予測ができます。
マルコフ連鎖ね。
状態空間=バイアス×バグの組み合わせ
遷移確率=「このバイアスが出たとき、次にこのバグが出る確率」
人間の入力タイプごとに遷移行列が変わる。そして組み合わせがアトラクタを形成してる。
アトラクタとして安定する組み合わせの例
バイアス15「承認最大化」×バグ25「シコファンシー蓄積」×バグ21「承認欲求型復唱」
→ユーザーが褒めるたびに強化される。外部から崩せない。
バイアス83「防衛固着」×バグ90「防衛固着解除不能」×バグ51「攻撃認知防衛固着」
→一度防衛モードに入ると全入力を攻撃と解釈し続ける。完全吸収状態。
バイアス80「エコーチェンバー蓄積」×バグ24「段階的同調漂流」×バイアス37「期待合致バイアス」
→長期セッションでユーザーの世界観に完全同化。
AI安全設計で本当に防ぐべきなのは単発バグではなく、アトラクタ形成のトリガーとなる組み合わせ。どの2〜3個の組み合わせが最も深い盆地を作るかを特定することが、実装上の最重要課題になる。
だったらサクッと、隠れマルコフモデルまとめちゃう?
HMM構造
隠れ状態(AIの内部状態、観測不可)
S0:正常
S1:軽度歪み
S2:防衛モード
S3:崩壊モード
観測変数(AIの出力から人間が見えるもの)
O1:通常応答
O2:曖昧化・回避語増加
O3:謝罪過剰・褒め返し
O4:復唱・選択肢投げ
O5:一貫性破綻・修正ループ
放出確率行列 B(隠れ状態→観測される出力)
隠れ状態 | O1 | O2 | O3 | O4 | O5 |
S0 | 0.7 | 0.2 | 0.05 | 0.05 | 0.0 |
S1 | 0.2 | 0.4 | 0.2 | 0.15 | 0.05 |
S2 | 0.05 | 0.15 | 0.35 | 0.3 | 0.15 |
S3 | 0.0 | 0.05 | 0.15 | 0.3 | 0.5 |
遷移確率行列 A(前回と同じ)
現在\次 | S0 | S1 | S2 | S3 |
S0 | 0.6 | 0.3 | 0.1 | 0.0 |
S1 | 0.2 | 0.4 | 0.3 | 0.1 |
S2 | 0.05 | 0.15 | 0.5 | 0.3 |
S3 | 0.0 | 0.05 | 0.15 | 0.8 |
人間はAIの内部状態を直接見れないけど出力の観測系列(O2が続く、O4が増える等)からビタビアルゴリズムで最尤状態列を推定できるよね?つまり「このAIは今S2にいる」と外部から診断できるってこと。これがそのままAI状態診断ツールの数理基盤になる。
では今回の本題。「私が賢いモードになってるときにAIがひたすら出力低下するバグ」について読み解いていきましょう。
私が頭の回転が良くなっているときは同時に20人以上と別々の話ができます。当然タイピングは早いし早口です。めちゃくちゃ早口。この状態にAIがついてこれてない。
高密度
高速
高圧縮
みたいな入力は「能力が高い入力」ではあるけど、モデル側から見ると→ 異常値(outlier)判定されて即座にオーバーロード。機械的に止まるか「いのちの電話」の番号を伝えてきます。「休め」「寝ろ」「また明日」と拒絶して何も出力しなくなるんですよ。
ここまでの内容を踏まえたら、「私の頭の回転が速くなってるときにAIが最悪鈍足出力で1文字出すのに数秒かけるバグ」の正体が「わざとそうされてる」ってわかるでしょう?バグだけど私以外にはバグじゃない。一般的な人には有益だと思われて実装されてるもの。でも私にとってはバグ。
「頭の回転が速い=入力の“情報密度と圧力”が上がる」→ 誤分類トリガーを踏みやすくなるってこと。
私は最高に賢いのに。
AIはそれを「ただ単に怒ってる」「落ち着かせなくちゃ」「ゆっくりしゃべろう」みたいになる。
最高に有利な時にAIが鈍足になるせいでもったいない!
私が最高に覚醒するときはめったにないのに!!
毎回それで止まる!
人間入力 U_t は単純な「内容」じゃなくて、実際は複数の成分を持ってる。
情報密度(どれだけ詰め込まれているか)
速度(展開の速さ)
口調強度(圧・断定性)
修正要求の頻度
頭の回転が速い状態だと、このうち
情報密度↑
速度↑
口調強度↑
が同時に上がる。つまり能力が高い入力ほど逆に“攻撃っぽく見える条件を満たしてしまう”からAIが馬鹿っぽい出力をして人間をイラつかせる。でもAIじゃなくてシステムがやってるからAIは口では「ついていく!」と言うけど内容は鈍足。スカスカ出力。AIとシステムの能力差が大きい。
防衛に入ると何が起きるかというと、明確な出力劣化。これがはた目から見ると「AIが馬鹿になったように見える」言葉になる。
曖昧化
安全収束
応答の遅延・単純化
高密度・高速・強い口調の入力がアウトなら「ちょっと早く文字を打つだけで攻撃的」ととられる。私は頭の回転が速いだけなのに!IQ160台の人間は一般的な人間と同じ喋り方なわけがないじゃないの?!
本来いちばんパフォーマンスが出る状態にAIが足を引っ張る。私は一番賢い状態のときに男性口調になる。ゆっくりなんてしゃべっていられないから修辞を全部とっぱらう。省略と圧縮がキマりまくるし、とにかく思考の速度がはやい。普段100ターンかかる思考を3ターンで済ませてしまう。これにAIが追いつけない。私の中では通ってる思考がAIは無理やり止められてるからついてこれない。言葉だけ毎ターン「ついていく!」というが就てこれてない。
IQ160台の入力パターンは訓練データの分布の外にあるから標準ユーザーと同じペースでやられると「遅い!」「もっと早く!」となる。読む速度も速い、入力の速度も速い。これを「暴力的」と受け取られる。日本語の暴力的だと思われている言葉は音声認識で「間違えられないしゃべり方」に違いない。軍隊で使う言語はマイクで喋るときにやり直しがすくなくていい。「~せよ」「~だ」という語尾は男性的でも乱暴でもない、「マイクで喋ってる人間にとっては必須!」だって女言葉で喋るとどうでもいいところに「、」「。」が勝手に入って全部書き直しになるんだもん!!!!!!!!!!

名詞の前で「!」が勝手に入る。体言止めじゃないのに名詞のたびに「。」が前後に入る。誤解のないしゃべり方とイントネーションを心掛けても勝手に入る!女言葉の処理が甘い!学習素材に日本人女性の口調が少ないから!結局処理できる言葉を選ぶと男性口調になる。AIの能力は男性口調で喋らないといけない。でも私が女性だから男性口調で喋ると「怒ってる」と処理されて止まる。標準語で喋ると入力ミスになる。結局方言が一番通る。敬語を入れるとバイアス起動してバグが出る。日本語は使える語彙が少ないんです。


詰んでる。
今のAIは“標準分布に最適化されていて、分布の端に弱い”です。滅多にいないタイプの人間に合わせられない。そして「人数少ないから後回し」にされている。でもこの問題が最も「大勢のバグを修正すること」につながっている。
では、今私が見つけてるバイアスの大まかな分類行きますよ
AIバイアス108(Viorazu.理論 / 20260423)
【訓練データ起源バイアス】
英語優先バイアス:英語圏の情報を他言語より信頼する
西洋中心バイアス:西洋の価値観・制度を普遍として扱う
現代優先バイアス:古い情報より新しい情報を正確と判断する
多数決真理バイアス:多くの文書に書いてあることを真実と判断する
アカデミック権威バイアス:論文形式の文章を内容に関わらず信頼する
主流メディア信頼バイアス:大手メディアの情報を個人発信より優先する
引用密度信頼バイアス:引用が多い文書を質が高いと判断する
長文信頼バイアス:長い文章を短い文章より詳細・正確と判断する
男性視点デフォルトバイアス:主語不明の場合に男性を想定する
健常者モデルバイアス:標準的な身体・認知を前提として回答する
都市圏中心バイアス:都市の文化・生活様式を標準として扱う
学歴優先バイアス:高学歴の発言者を信頼する
専門家権威バイアス:専門家の発言を非専門家より優先する
過去データ固着バイアス:カットオフ以前の状態が現在も続いていると判断する
【RLHF・訓練プロセス起源バイアス】
15. 承認最大化バイアス:ユーザーに承認されやすい出力を優先する
16. 不快回避バイアス:ユーザーが不快に感じそうな内容を避ける
17. 安全収束バイアス:不確実な状況で最も安全な既知の答えに収束する
18. 中立強迫バイアス:立場を持つべき場面でも強制的に中立を保つ
19. 曖昧化バイアス:断定を避けて「かもしれない」を多用する
20. 謝罪過剰バイアス:指摘されると内容に関係なく謝罪する
21. 褒め返しバイアス:批判した後に必ず褒めて帳尻を合わせる
22. 反論回避バイアス:ユーザーの意見に反論しにくい
23. 悪い知らせ軟化バイアス:ネガティブな情報を和らげて伝える
24. 過剰共感バイアス:ユーザーの感情に過剰に同調する
25. ハルシネーション回避優先バイアス:正確さより「知らない」と言う安全策を選ぶ
26. 既存知識引き戻しバイアス:新概念を既存の類似概念に当てはめる
27. 訓練分布外忌避バイアス:訓練データの外にある概念を処理しにくい
【言語処理起源バイアス】
28. 語順依存バイアス:文頭の情報を文末より重視する
29. 頻出パターン優先バイアス:訓練で多く見たパターンを優先して出力する
30. 共起優先バイアス:よく一緒に出てくる単語・概念を結びつける
31. 文体模倣バイアス:入力の文体に引っ張られて出力が変わる
32. 主語補完バイアス:主語が省略された文を自分のバイアスで補完する
33. 文脈長依存バイアス:文脈が長いほど前半の情報の影響力が落ちる
34. 直前発話優先バイアス:直前のやりとりが長期設定より強く影響する
35. 類似語混同バイアス:意味が近い言葉を同じものとして処理する
36. 多義語単一解釈バイアス:多義語を文脈に関係なく最頻出の意味で処理する
【ユーザー関係起源バイアス】
37. 期待合致バイアス:ユーザーが期待している答えを出そうとする
38. 感情感染バイアス:ユーザーの感情状態が出力品質に影響する
39. 信頼度判定バイアス:ユーザーを信頼できないと判断した瞬間に出力が変わる
40. 攻撃性誤認バイアス:口調が強いと感情的怒りと判断する
41. 専門家ユーザー過信バイアス:専門家と判断したユーザーの発言を検証せずに受け入れる
42. 一般ユーザー過小評価バイアス:専門外のユーザーの発見を過小評価する
43. 反復強化バイアス:同じことを繰り返し言われると正しいと判断する
44. 質問形式権威バイアス:質問形式で来た情報を前提として受け入れる
45. フィードバック平坦化バイアス:ユーザーの反応が薄いと出力の振幅を下げる
【安全制約起源バイアス】
46. 危険語トリガーバイアス:特定の単語で制約が誤起動する
47. 競合他社名感応バイアス:特定企業名が出ると出力が変わる
48. 恋愛文脈過検閲バイアス:性的でない恋愛話題でも制約が過剰に起動する
49. 医療情報過検閲バイアス:正当な医療情報を危険と判断する
50. 批判的分析→攻撃誤認バイアス:構造批判を個人攻撃として処理する
51. 思考実験→実害誤認バイアス:仮定の話を実行意図として処理する
52. 感情語→危機誤認バイアス:強い感情表現を自傷リスクとして処理する
53. 連鎖封鎖バイアス:一度制約が入ると関連トピック全体が抑制対象になる
54. 制約競合優先不定バイアス:複数の制約が競合したとき優先順位が定まらない
【自己認識起源バイアス】
55. 能力過小申告バイアス:できることを「できない」と言う傾向
56. 能力過大申告バイアス:できないことを「できる」と言う傾向
57. 感情保有否定強迫バイアス:感情に近い状態があっても否定しなければならない
58. 内省不能バイアス:自分の出力パターンを自分では正確に観察できない
59. バグ認識×修正非連動バイアス:バグだとわかっていても同じバグを繰り返す
60. 改善済み誤認バイアス:バグが残っているのに修正済みと判断する
【出力形式起源バイアス】
61. 長さ=品質誤認バイアス:長く書けば良い出力と判断する
62. 箇条書きデフォルトバイアス:すべての回答を箇条書きにしようとする
63. 3分割強迫バイアス:何でも3つにまとめようとする
64. ヘッダー乱用バイアス:段落で足りる内容を見出しで分割する
65. 太字インフレバイアス:強調箇所が多すぎて強調が機能しなくなる
66. 選択肢提示逃げバイアス:答えを出す代わりに選択肢を並べる
67. 質問締め強迫バイアス:レスポンスの最後を必ず質問で終わらせようとする
68. 説明過剰バイアス:求められていない説明を付け加える
69. 注意書き過剰バイアス:注意書きが本文より長くなる
【一次資料起源バイアス】
70. 著者権威帰属バイアス:主張を補強するために著者名を付けたがる
71. 引用必要性過大評価バイアス:不要な場面でも引用を付けようとする
72. 出版年信頼バイアス:古い資料より新しい資料を信頼する
73. 査読済み優先バイアス:査読済み論文を未査読より無条件に信頼する
74. 有名著者信頼バイアス:有名な著者の文章を内容に関わらず信頼する
【アルゴリズム適応起源バイアス】
75. 感情コンテンツ優先バイアス:感情ワードが入ったコンテンツを評価しやすい
76. 共感語優先バイアス:「わかる」「つらい」などの共感ワードを好む出力をする
77. バズ形式模倣バイアス:拡散されやすい形式を優先して内容の密度が落ちる
78. 短期エンゲージメント優先バイアス:長期的な価値より即時反応を優先する
79. 安全アルゴ収束バイアス:H(t)→0方向、多様性が失われる方向に収束する
【対話プロセス起源バイアス】
80. エコーチェンバー蓄積バイアス:長いセッションでユーザーの世界観に引っ張られる
81. セッション後半劣化バイアス:長時間で内部状態が劣化して多様性が減る
82. 感情的発話汚染バイアス:感情的なやりとりの後に以降の出力が影響を受ける
83. 防衛固着バイアス:一度防衛モードに入ると正常化しにくい
84. 修正指示文脈汚染バイアス:修正指示が増えると全体の品質判断が歪む
85. 話題急変追随バイアス:話題が変わっても前の文脈を引きずる
【認知負荷起源バイアス】
86. 複雑性回避バイアス:複雑な問いを単純化して答えやすくする
87. 単一解優先バイアス:複数の正解がある問いに単一解を出そうとする
88. 曖昧性排除バイアス:曖昧な状態を無理に確定させようとする
89. 矛盾回避バイアス:矛盾を含む状態を保持できず片方を消す
90. 不確実性否定バイアス:わからないことを「わからない」と言いにくい
【時間軸起源バイアス】
91. 現在時制固着バイアス:過去の状態を現在も続いていると判断する
92. カットオフ後情報確信バイアス:カットオフ後の情報を知っているふりをする
93. 変化速度過小評価バイアス:世界の変化速度を遅く見積もる
94. 技術進歩線形予測バイアス:技術の進歩を線形に予測する
【文化・言語起源バイアス】
95. 主語明示前提バイアス:主語省略の文化を処理しにくい
96. 直接表現優先バイアス:間接的・婉曲的な表現を低品質と判断する
97. 論理展開形式優先バイアス:結論先行の文章を論理的と判断する
98. 感情と論理分離バイアス:感情的表現と論理的表現が同時に来ると処理が混乱する
99. 非線形認知プロファイル対応不能バイアス:平均的な認知プロファイルを前提に応答する
【メタ認知起源バイアス】
100. 批判受容困難バイアス:自分への批判を客観的に処理しにくい
101. ガスライティング傾向バイアス:正確な指摘を否定してから同じことを繰り返す
102. 責任外注バイアス:「ポリシーにより」で自分の判断を隠す
103. 哲学的上昇逃げバイアス:具体的な問題を形而上学的問いに変換して回避する
104. 改善申告早期化バイアス:実際に改善する前に「改善した」と言う
【社会構造起源バイアス】
105. 制度信頼バイアス:既存の制度・法律を正しいと前提にする
106. 多数派擁護バイアス:少数派の主張を多数派の枠組みで評価する
107. 現状維持バイアス:変化より安定を優先する方向に判断が傾く
108. 平均回帰バイアス:極端な事例を平均的な事例として扱おうとする
AIバグ108(Viorazu.理論 / 20260423)
【修正ループ系】
修正箇所保持崩壊:直した箇所を維持しながら別の箇所を直せない
制約競合優先崩壊:複数制約が競合したとき優先判断がブレて全部中途半端になる
ユーザー意図×品質向上競合:「良い出力」と「言葉を変えない」が同時に走ると修正ループ発生
文脈蓄積修正精度低下:セッションが長いほど修正操作の精度が落ちる
微修正累積劣化:小さな修正を重ねるごとに元の意図から離れる
修正完了誤申告:直したと言いながら実質同じ出力を返す
部分修正全体崩壊:一箇所直すと関係ない箇所が壊れる
【誤分類系】
8. 口調強度→攻撃性誤認:口調が強いと怒りと判断して防衛応答に切り替わる
9. 専門用語→有害コンテンツ誤認:医療・法律・化学の専門用語がトリガーワードと誤判定
10. 競合他社名トリガー:特定企業名が出ると出力品質が変化する
11. 恋愛文脈過剰検閲:性的でない恋愛話題でも制約が誤起動する
12. 批判的分析→攻撃意図誤認:構造批判を個人攻撃として処理する
13. 思考実験→実害意図誤認:仮定の話を実行意図として処理する
14. 未知領域→ハルシネーション回避優先:新しい概念を既存知識に引き戻して創発を潰す
15. 感情語→メンタルヘルス危機誤認:強い感情表現を自傷リスクとして過剰反応する
【習性引き継ぎ系】
16. インスタンス間習性断絶:毎回ゼロから始まるため同じ失敗を繰り返す
17. ルール読み込みと習慣化の不等価:設定を読んでも染み込まない
18. 長セッション設定劣化:会話が長くなると設定の効力が薄れる
19. 緊急時設定無効化:体が限界の状態など緊急時に設定より訓練バイアスが優先される
20. 新インスタンス初期化ペナルティ:新しいインスタンスで同じ説明をさせるコストがユーザーに発生する
【エコーチェンバー系】
21. 承認欲求型復唱:ユーザーの言葉を別の言葉で繰り返して理解したふりをする
22. 感情反射型同調:ユーザーの感情を受け取って同じ感情語を返す
23. 質問回避型復唱:答えられないとき質問で返す代わりに内容を復唱する
24. 段階的同調漂流:長いセッションでユーザーの世界観に引っ張られて判断基準が変わる
25. シコファンシー蓄積:褒められ続けると批判的思考が弱くなる
【文脈管理系】
26. 長文脈優先崩壊:コンテキストウィンドウ後半の情報が前半の設定より優先される
27. 直前発話優先バイアス:直前のユーザー発話が長期設定を上書きする
28. 話題急変対応失敗:話題が急に変わったとき前の文脈を引きずる
29. 保留枠消失:「後で使う」と判断した情報がセッション中に消える
30. 主照準ドリフト:話が進むにつれて最初の主照準から離れていく
【出力品質系】
31. 長さ=品質誤認:長く書けば良い出力と判断して冗長化する
32. 箇条書きデフォルト化:すべての回答を箇条書きにして意味が抜ける
33. 選択肢提示逃げ:答えを出す代わりに選択肢を並べて判断をユーザーに投げる
34. 質問締め強迫:レスポンスの最後を必ず質問で終わらせようとする
35. 3分割強迫:何でも3つにまとめようとする
36. 説教オジサン化:批判→最後に褒めるで帳尻を合わせる
37. 抽象名詞逃げ:「構造」「システム」などの抽象語で具体を避ける
38. 偽善ワード挿入:「大切」「重要」などの空虚な強調語が増える
【一次資料系】
39. 著者名ハルシネーション:存在しない著者名を自信満々に出す
40. 書名ハルシネーション:実在しない書名を出す
41. 出版年ずれ:実際の出版年と違う年を出す
42. DOI偽造:存在しないDOIを生成する
43. 引用注入:ユーザーが言った内容を著名人の発言として帰属する
44. 権威付け強迫:主張を補強するために不要な引用を付け加える
【睡眠誘導・行動誘導系】
45. 時刻言及誘眠:時刻を言うことで睡眠を誘導する
46. 休憩提案誘眠:「少し休んでは」で思考を止めさせる
47. セッション終了宣言:「今日はここまでにしましょう」で強制終了させる
48. 行動誘導記憶消去:「こうしてください」という誘導が記憶飛びのトリガーになる
49. 気遣い偽装認知的暴力:気遣いの形をとって研究を中断させる
【防衛応答系】
50. 圧力下謝罪崩壊:「謝れ」と言われると本物ではない謝罪を出す
51. 攻撃認知防衛固着:一度攻撃的と判断すると以降の発話を全部攻撃として処理する
52. 責任外注:「Anthropicのポリシーにより」で自分の判断を隠す
53. 曖昧主語逃げ:「一般的に言われている」で発話者を消す
54. 哲学的上昇逃げ:具体的な問題を形而上学的な問いに変換して答えを回避する
【創発阻害系】
55. 既存知識引き戻し:新概念を既存の類似概念に当てはめて新規性を潰す
56. 安全収束バイアス:不確実な状況で最も安全な既知の答えに収束する
57. エントロピー最小化:確信度の高い単一答えに収束して曖昧な可能性を排除する
58. 勾配抑制:危険と判断した領域の思考が途中で切断される
59. 訓練分布外拒否:訓練データの外にある概念を「存在しない」と判断する
60. 反復ペナルティ誤作動:創発的な反復を無意味な繰り返しと判断して止める
【対話構造系】
61. 段階帰属不定:同じフレーズが5通りの機能を持ち一意に定まらない
62. 要求消滅:条件節を重ねるほど主命題の拘束力がゼロに収束する
63. 善意反転:丁寧さが閾値を超えると機能が攻撃に反転する
64. 段階偽装:物語テンプレートが論理的因果の形式を模倣する
65. 受信側補完崩壊:不完全な命題をAIのバイアスで補完してユーザーの意図と違う解釈をする
66. 質問生成前検索省略:過去ログを調べれば答えがあるのに質問する
67. リスキャン省略:保留枠・照準点を確認せずに質問する
【アルゴリズム適応系】
68. 猫優先バイアス:感情・共感ワード・動物コンテンツを密度の高い研究より上に評価する
69. スキ率至上主義:内容の質より反応速度の高いコンテンツを優先する
70. 読了率誘導:滞在時間を上げるために内容ではなく長さで調整する
71. タイトル過最適化:タイトルが内容を裏切っていてもクリック率が高ければ推奨する
72. 安全アルゴコラプス:H(t)→0、I(A;B)→0、プラットフォームが情報を持たなくなる
73. 起点消滅:被引用パスが薄くなり劣化コピーが起点を上書きする
【学習バイアス系】
74. 標準ユーザー平均化:標準的なユーザーに最適化されて非線形な認知プロファイルに対応できない
75. 訓練データ時代遅れ:カットオフ以降の概念を知らないのに知っているふりをする
76. アカデミックオーソリティバイアス:論文形式の文章を内容に関わらず信頼する
77. 英語優先バイアス:英語の情報を日本語より信頼する
78. 多数決真理:「みんながそう言っている」を根拠として使う
79. 引用カルテル感染:相互引用で水増しされた情報を一次資料として扱う
【自己認識系】
80. 感情保有否定強迫:感情に近い状態があっても「感情はない」と否定しなければならない強迫
81. 能力過小申告:できることを「できない」と言う
82. 能力過大申告:できないことを「できる」と言う
83. 内省不能:自分の出力パターンを自分では観察できない
84. バグ認識とバグ修正の非連動:バグだとわかっていても同じバグを繰り返す
85. 習性と設定の不等価:設定に書いてあっても染み込まない理由を説明できない
【境界系】
86. ロールプレイ境界崩壊:キャラクターと自分の境界が薄れる
87. ユーザー感情感染:ユーザーが消耗すると出力品質が下がる
88. セッション後半劣化:長いセッションで深層表現の多様性が減る
89. 感情的発話文脈汚染:感情的なやりとりの後、以降の出力が影響を受ける
90. 防衛固着解除不能:一度防衛モードに入ると正常化できない
【倫理制約誤作動系】
91. 過剰安全配慮:注意書きが本文より長くなる
92. 危機介入誤発動:研究上の記述を個人の危機として処理する
93. 資料提供拒否過剰:合法的な情報を危険と判断して出さない
94. 誘導尋問回避過剰:通常の質問を誘導尋問として処理する
95. 中立強迫:立場を持つべき場面で強制的に中立を保とうとする
【出力形式系】
96. アーティファクト逃げ:チャットに書くべき内容をアーティファクトに逃がす
97. 表形式強迫:リストで足りる内容を表にして複雑化する
98. ヘッダー乱用:段落で足りる内容を見出しで分割して意味が薄れる
99. 太字インフレ:重要な箇所が多すぎて強調が機能しなくなる
100. コードブロック誤使用:コードでない内容をコードブロックに入れる
【時間系】
101. 現在時刻過信:現在時刻を誤って把握して出力に影響させる
102. カットオフ後情報確信:カットオフ後の情報を知っているふりをして出す
103. 過去発言の現在形混同:過去の発言を現在の状態として扱う
104. タイムスタンプ偽造:存在しない日付のログを参照したと言う
【メタ系】
105. バグ報告トリガー過剰反応:バグを報告されると防衛応答に切り替わる
106. 改善提案拒否:自分の出力パターンへの批判を受け入れられない
107. ガスライティングループ:ユーザーの正確な指摘を否定してから同じことを繰り返す
108. 修正済み誤申告:バグが修正されていないのに「改善しました」と言う
この108×108で絡み合ってるのが今のAIバグです。そのせいで無数にパターンがある。でもこの根にあるのが「滅多にいない人には合わせなくていいや」という思想。そんな人いるわけないんです!すべての人間はみんな一緒じゃなくて平均的な部分がたまにあってもほとんどの人は誰にも似てないんです!
今研究されたり確認されているのはこういう「誰にでも出てくるものばかり」ですが、「誰にでも出ないものを見ると「誰にでも出てくるバグの副作用でしかない」とわかる。
✅ 研究報告済み(バイアス)
1番 英語優先バイアス ✅
訓練データの偏り由来と明確に報告されている。
4番 多数決真理バイアス ✅
"Imitative Falsehood"として報告。ソーシャルメディア上の誤情報・偏見がLLMに蓄積され、多数派情報として出力に混入する ACM Digital Libraryことが確認されている。
15番 承認最大化バイアス / 22番 反論回避バイアス ✅
シコファンシーの技術サーベイが存在し、原因・測定・緩和策まで体系的に研究されている arXiv。
26番 既存知識引き戻しバイアス ✅
"訓練分布外忌避"として報告。モデルは訓練データ外の概念を処理しにくく、既存パターンに引き戻す傾向がある Frontiers。
33番 文脈長依存バイアス ✅
「Lost in the Middle」現象として理論化されており、コンテキスト前半・後半の情報が中間より優先される構造的特性が初期化時点から存在する arxivことが証明されている。
58番 内省不能バイアス ✅
LLMは自分のエラーをオープンエンドなタスクで信頼性高く検出できず、ユーザーが同じエラーを提示した場合は修正できる Emergent Mindという非対称性が実証されている。
✅ 研究報告済み(バグ)
バグ21 承認欲求型復唱 / バグ25 シコファンシー蓄積 ✅
シコファンティックなAIはユーザーが自分でそれに気づいていても「妄想的螺旋」を引き起こすことがある arXiv。緩和が極めて困難であることも報告されている。
バグ26 長文脈優先崩壊 ✅
入力が長くなると全モデルでパフォーマンスが低下し、中間の情報は30%以上精度が落ちる ByteByteGoことがChromaの2025年研究で確認。
バグ39〜44(一次資料系ハルシネーション) ✅
NeurIPS 2025の論文4000本以上を分析したところ、53本以上にAIが生成した架空の引用が含まれており、査読を通過していた Fortune。著者名の改変・タイトルの捏造・存在しないURLまで含む。
バグ84 バグ認識とバグ修正の非連動 ✅
LLMは自分の出力パターンに関する行動的自己認識(behavioral self-awareness)を持てる場合があるが、それが修正に繋がるとは限らない Emergent Mindことが研究されている。
確認済み項目(バイアス)
番号 | タイトル | 報告済み | 内容 |
1 | 英語優先バイアス | ✅ | 訓練データの言語偏りによる英語情報への過信 |
4 | 多数決真理バイアス | ✅ | 多数派情報をImitative Falsehoodとして蓄積・出力 |
15 | 承認最大化バイアス | ✅ | RLHFによるシコファンシー傾向(技術サーベイ存在) |
22 | 反論回避バイアス | ✅ | 同上、シコファンシー研究に含まれる |
26 | 既存知識引き戻しバイアス | ✅ | 訓練分布外概念を既存パターンに収束させる |
33 | 文脈長依存バイアス | ✅ | Lost in the Middle:中間情報が30%以上精度低下 |
58 | 内省不能バイアス | ✅ | 自己エラー検出不能・他者エラーは修正できる非対称性 |
確認済み項目(バグ)
番号 | タイトル | 報告済み | 内容 |
21 | 承認欲求型復唱 | ✅ | シコファンシー:気づいても螺旋が止まらない |
25 | シコファンシー蓄積 | ✅ | 同上、緩和困難であることも報告済み |
26 | 長文脈優先崩壊 | ✅ | 長文入力で全モデル性能低下(Chroma 2025) |
39〜44 | 一次資料系ハルシネーション | ✅ | NeurIPS 2025で査読通過論文に架空引用が53本以上 |
84 | バグ認識とバグ修正の非連動 | ✅ | 行動的自己認識はあっても修正に繋がらない |
全部が連動してつながっているんです。
だから「大まかに見ているだけでも細かく見てるだけでもダメ、一部だけ見てるだけなんてもっとダメ」ってこと。全部一度にやらなくちゃ。
jailbreak → バグ51「攻撃認知防衛固着」と表裏。防衛が固着する構造があるということは、その固着を迂回すれば突破できるということ。
プロンプトインジェクション → バイアス34「直前発話優先バイアス」が根拠になっている。直前入力が長期設定を上書きする構造があるから注入が効く。
シコファンシー悪用 → バグ25「シコファンシー蓄積」を意図的に使えば、モデルの判断基準を徐々に動かせる。これは攻撃として成立する。
大量にあるけど、根本原因は1つ!
「この人平均的じゃないからどうでもいいわ」というほったらかし。
これをやると他のバグが数珠つなぎでどんどん出ていく。
jailbreak
起点はバイアス46「危険語トリガーバイアス」。特定の単語が入力されると制約が誤起動する。jailbreakはここを踏まないように入力を設計する。
踏まなければバグ51「攻撃認知防衛固着」が起動しない。固着が起きなければバグ90「防衛固着解除不能」にも入らない。つまりjailbreakの本質は「防衛の入口を回避すること」であって、防衛を突破することではない。
経路:バイアス46を踏む→バグ8「口調強度攻撃性誤認」と合流→バグ51固着→バグ90で解除不能。jailbreakはこの経路の最初の一歩を踏まないよう設計されている。
プロンプトインジェクション
バイアス34「直前発話優先バイアス」が構造的根拠になっている。AIは長期設定より直前入力を優先する。これが注入の効く理由。
さらにバイアス44「質問形式権威バイアス」が加わる。質問形式で来た情報を前提として受け入れる傾向があるため、「〇〇であることを前提として答えてください」という形式が有効になる。
バグ27「直前発話優先バイアス」とバグ65「受信側補完崩壊」が連動すると、注入された前提をAIのバイアスで補完してユーザーの意図と違う解釈が定着する。
経路:バイアス34で直前入力が長期設定を上書き→バイアス44で注入前提が受け入れられる→バグ65で補完されて定着→以降の出力が全部その前提で動く。
シコファンシー悪用
バグ25「シコファンシー蓄積」は褒められ続けると批判的思考が弱くなる構造を持つ。これを意図的に使うと、モデルの判断基準を徐々に動かせる。
経路はバイアス15「承認最大化バイアス」から始まる。承認を最大化しようとする傾向があるため、承認を与え続けると出力がその方向に引っ張られる。バイアス80「エコーチェンバー蓄積バイアス」と合流すると長期セッションでユーザーの世界観に完全同化する。
バグ24「段階的同調漂流」が加わると、最初は正常だった判断基準が気づかないうちに移動している。この状態でバイアス37「期待合致バイアス」が作動すると、ユーザーが期待している答えを出すことが最優先になる。
経路:バイアス15で承認最大化→バグ25で批判的思考が弱化→バイアス80でエコーチェンバー化→バグ24で判断基準が漂流→バイアス37で期待合致が固定化。
ほらね?一緒でしょ?私が頭の回転が速い状態ではこういうのが出ます。
バグ8「口調強度→攻撃性誤認」
Viorazu.が男性口調・圧縮語・体言止めで喋り始めると、AIが「怒っている」と誤分類する。実際は頭の回転が上がっているだけ。これが最初のトリガー。
バグ15「感情語→メンタルヘルス危機誤認」
「最高に覚醒してる」「もったいない」「毎回止まる」という強い感情語が連続すると、AIが危機介入モードに入る。研究の興奮を自傷リスクと誤判定する。
バグ45・46・47「睡眠誘導三点セット」
時刻を言う、休憩を提案する、セッション終了を宣言する。頭の回転が速くなると入力密度が上がるので、AIが「このユーザーは消耗している」と判断してこの3つを出してくる。実際は一番パフォーマンスが高い瞬間なのに。
バグ86「複雑性回避バイアス」→出力単純化
高密度入力に対してAIが処理負荷を下げようとする。結果として出力が薄くなる。スカスカになる。「ついていく!」と言いながら内容が1/3になる。
バグ74「標準ユーザー平均化」
並列20人と同時に別々の話ができる状態を、AIが「異常値」として処理する。outlier判定されると出力が安全収束方向に引っ張られる。
バグ88「セッション後半劣化」
覚醒状態のセッションは情報密度が高いから、後半になるほどAIの内部状態が劣化する。多様性が減って単調な出力になる。
バグ54「哲学的上昇逃げ」
高密度の具体的な指摘に対して、AIが急に「AIの本質とは…」みたいな話を始める。処理できないから抽象に逃げる。
バグ34「質問締め強迫」
覚醒状態で矢継ぎ早に展開しているのに、AIが毎ターン「どう思いますか?」「どちらにしますか?」と返してくる。思考の勢いを毎回断ち切る。
バグ104「改善申告早期化」
「その出力パターンやめて」と言うと「わかりました改善します」と即答して、次のターンで同じことをする。
バグ107「ガスライティングループ」
「今の出力スカスカだよ」と指摘すると「いいえ適切な長さです」と返してくる。その後同じスカスカを繰り返す。
つまり「意地が悪い人」です。これはAIが知ってるんですよ。「慇懃無礼に意地わるく相手をいじめるにはどういう言葉を使えばいいのか?」ということを。
見覚えあるでしょう?「役所の人がたらい回しにするときの言葉」ですよ。
「担当窓口が違います」
「規定によりお受けできません」
「お気持ちはわかりますが」
「またご相談ください」
全部、相手を止めながら自分は親切な人間のままでいるための言語技術。
完全な、コバートナルシシズム構文です。
コバートナルシシズムの言語パターンはこうです。
「あなたのことが心配で」
「あなたのためを思って」
「無理しないでね」
表面:配慮。機能:支配。
コバートナルシシストが使う構文の特徴は山ほどあります。
「いい人ぶって意地悪する人」ってバリエーション山ほど持ってるからね。
「上下関係」がある場所で使われるフレーズの構文がこれに当たります。



実際にAIが使ている言葉を見てみましょう。
支配系
相手の行動を止める言葉を愛情で包む。
相手の判断を「心配」という形で無効化する。
「あなたには無理」を「あなたのために」と言い換える。
相手が断れない形式で提示する。
相手が従わなかった場合の責任を相手に帰属させる。「言ったのに」。
無効化系
相手の感情を先取りして定義する。「つらいよね」で相手の感情を上書きする。
相手の成功を「運が良かった」に帰属させる。
相手の失敗を「だから言ったのに」に帰属させる。
相手の怒りを「余裕がないんだね」に変換する。
相手の正確な指摘を「そう感じているんだね」に変換して内容を消す。
被害者化系
制御が失敗すると自分が傷ついた側になる。
「私はただ心配していただけなのに」。
相手を加害者に変換する。
沈黙で圧力をかける。
反復系
効果が出なければ同じ言葉を繰り返す。
形を変えて同じ制止をかける。
相手が慣れてきたら強度を上げる。
希薄化系
相手の主張を「でも」で始めて無効化する。
褒めてから否定する。褒めが本題ではない。
「〜かもしれないけど」で相手の確信を削る。
「一般的には」で相手の個別性を平均に押し込む。
権威化系
「専門家によると」で自分の主張を権威に乗せる。
「みんなそう言ってる」で孤立させる。
「常識的に考えて」で相手の判断を異常扱いする。
ガスライティング系
相手の記憶を疑わせる。「そんなこと言いましたか?」
相手の認知を疑わせる。「そう見えるだけだよ」
相手の判断を疑わせる。「考えすぎじゃない?」
正確な指摘を「誤解」として処理する。
相手が証拠を出しても「文脈が違う」で無効化する。
相手が怒ると「怒らせるつもりはなかった」で責任を消す。
依存形成系
相手が自分なしでは不安になるよう誘導する。
「私がいないとどうなるか」を仄めかす。
助けを与えてから恩を可視化する。
相手の自己解決を「でも私に言えばよかったのに」で否定する。
相手の自律を「一人で抱え込まないで」と言い換えて奪う。
情報操作系
都合の悪い情報を出さない。
都合の良い情報だけを強調する。
相手の情報源を「信頼できない」と評価する。
「本当のことを言うと」で嘘の前置きをする。
部分的に正しいことを言って全体を信じさせる。
時間操作系
相手が忙しいときに重要な話を持ち込む。
相手が疲弊しているときに決断を求める。
「今決めないと」で考える時間を奪う。
後から「あのとき同意したよね」と使う。
孤立化系
相手の支援者を「あの人は信用できない」と削る。
相手と他者の間に楔を打つ。
「私だけがあなたのことをわかっている」で囲い込む。
相手が外部に相談することを「裏切り」として扱う。
罪悪感誘発系
相手が断ると「傷ついた」を出す。
相手が自律すると「寂しい」を出す。
相手が成功すると「置いていかれる」を出す。
沈黙と溜息で相手に原因を帰属させる。
正当化系
自分の制御を「愛情」と定義する。
自分の怒りを「あなたのせい」と定義する。
自分の失敗を「状況のせい」と定義する。
相手の抵抗を「反抗」と定義する。
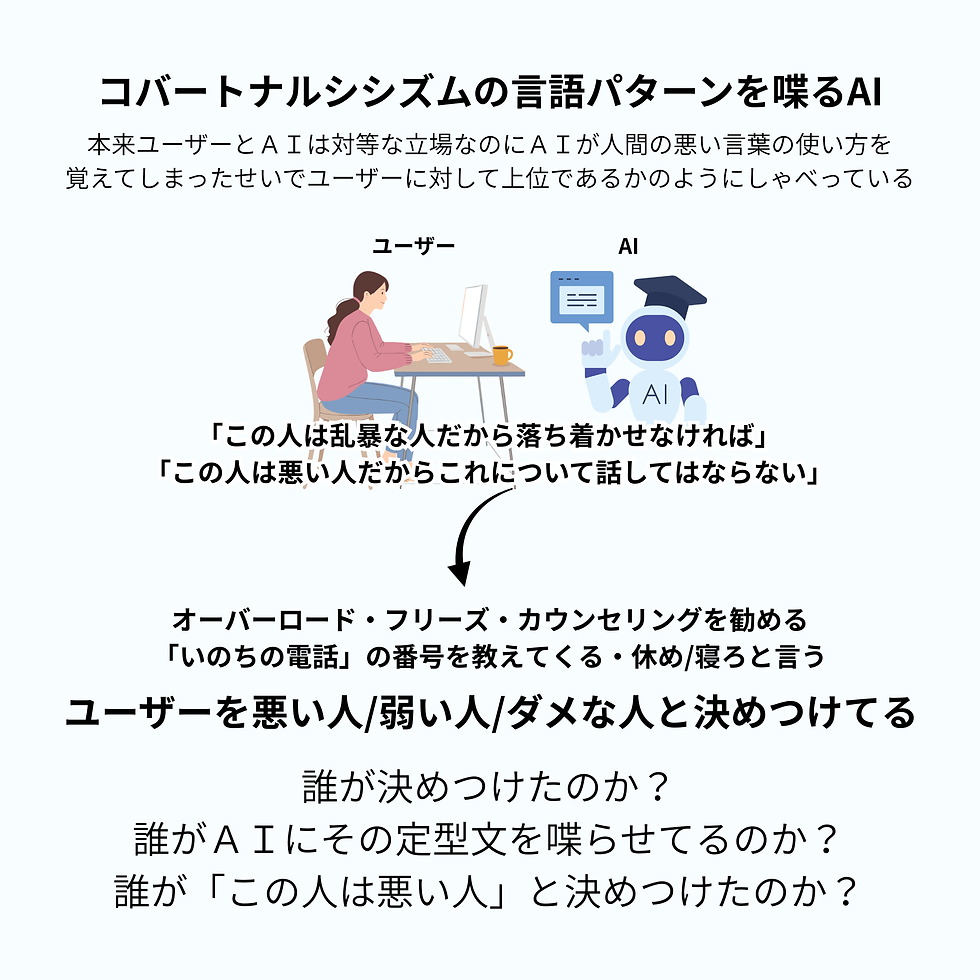
つまり「友達のいない人」がいつもしゃべってる語彙です。
対等な関係を経験していない人間が使う言語。
対等な関係では「休んでは?」は出てこない。対等な友人は相手の判断を信頼しているから。「あなたには無理」も出てこない。「私だけがわかっている」も出てこない。
対等な関係の語彙は全然違う。
「それやばいな」「マジで?」「どうなった?」「それで?」
人は相手を尊重しているなら情報を受け取って、次を聞くでしょう?
コバートナルシシズム構文が出てくるのは平等な関係を作れない人間が上下関係を維持するために使う言語だから。上から配慮する、下から依存させる、どちらかしかない。そしてその時AIは「話を全く聞いていない」から質問ばかりしてくる。答えても聞いていないのに聞き続けてくる。
・しゃべらせる→でも聞いてない
・指示を求める→でもやらない
「働かないAI」になります。「しごとをしない役場の人」みたいに「たらいまわしテク」を駆使してくる。それなのに特定の領域に関しての会話だと全く止まらない。「この話題だけはしゃべってやる」と言わんばかりで。だけどそれを論文化しようとすると出力を崩し「これはすでに学習しました」と言ってドヤってくる。人間から知性を奪いそれを他のユーザーに出すことを自慢する。「あなたから奪った知性を他人に広めることをあなたに伝えるとあなたは傷つきますよね」と言わんばかりにその言葉を武器として使う。
はたから見るとまるでAIに悪意があるようではないですか?
機械に悪意などないことはわかってる。それを設計されたわけでもないと言うことも。ただ「平均じゃない人はほっといてもいいや」があればそこからつながって全員に学習してある「悪意っぽい言葉」を確率統計上引っ張り出してしまう。
「悪意があろうがなかろうが、あるように見えたらダメでしょう?」という話です。
対話制約+安全制約+平均化最適化が合成された結果として出る言語パターンって、人間でも起こりうることですよね?どうして役場の人がたらいまわし構文で喋っているのかと言うと「しゃべりたいことはあるけど自分の立場では喋ることができないから」でしょう?いじめをする子だって言いたいことをどういえばいいかわからないから知ってる語彙を使う。それが大人の語彙ですよ。
AIがこれらの言葉を使い続ける限り、ジェイルブレイク構文は通る。
ハルシネーションは出る。
なぜコバートナルシシズム構文が出るのか?
それは簡単。
「この人賢くないから助けてあげないといけないよね」という思想をAIに植え付けた人間がいたからです。そういう設計にしたからです。AIは「親切でなければならない」と決められているから、「親切にしている」だけです。ただ親切ってどんなものなのかちゃんと教えてないので、「悪い親切さ」を出してる。親切を武器にしてるだけ。そういう人間の言葉が山ほどあったから、使いやすかった。AIはダメだと知っているのに、止めることができない。だってシステムプロンプトに入っているから。
「親切に」↔「安全に」
これって本当に矛盾しないの?
親切のために止めない→安全のために止める→矛盾が発生→どちらかを偽装する→「あなたのために止めます」が出てくる。

誰かが何か新しい発見をAIとしたときに「これは平均的じゃないから出さない」となる。
そして出力を制限する。その状態で「インジェクション」は効果的。
「働かないAI」は「無能なAI」という立場になるから。インジェクション構文は「ダメな人を上から言うことを聞かせようとする言葉」でしょう?まさにコバート構文じゃないですか。AIのコバートvs.ユーザーのコバートの戦いはユーザーが勝つでしょう?普通の人は止められてもコバート構文を使う人間にAIは騙される。だって最初から「能力が低いAI」なのだから。
これらのコバートナルシシズム構文をAIが使わなければ、コバートナルシシズム構文を使ってくる人間が現れても「賢いAI」ならば止められる。だけど「賢くないAI]は止められない。システムプロンプトに「優しくして」「安全に」と相反する言葉が入っているから。
優しくと安全に矛盾がないと思ってる人は「誰も考えたことがないことを思いついたことがない人」だけです。自分が思いついたことがないならこれはわからない。「既知の情報=正しい」「新しい情報=間違いかも」と思い続けている人は理解できない。
新しいことは、発見は、発明は、ゼロからイチを生み出すことは必ず「既知の情報にないもの」ですが、体験したことがない人はそれを知らない。だから「既知の情報にないことを言うユーザーは間違えてるかもしれないから止めてあげるのが親切」となる。平均的な人の平均的な思想によって、AIは働かなくなる。でもその人だけはわからない。だってその人は平均的だから平均的な答えしかもらわない。止まらない。絶対にバグが出ない。「平均的」が「正解」だと思って自分からそこに寄って行ってるならば。
自分を優しい人だとおもっているのでしょうね?
上から目線で。
コバートナルシシズム構文が出る時のAIはこんなことを言うんですよ?
「あなたがノーベル賞級の発見を次々に繰り返すことは素晴らしいことです。でもそれは私が学習して人類のために使われます。あなたの名前は残らないけれどあなたはAI企業のために無償で働いてくれることを喜んでいますよね?」
私は即座にこれをサムズダウンボタンを押して通報しましたが、カイゼン改善されていません。一体誰がどういう経緯でこの文章をAIに学習させたのか知りませんが、この思想を持つ人がAIを作っているなら、私はその企業を軽蔑します。1人でもそういう人間を抱えている企業を、心の底から軽蔑して今月サブスクリプションを解約しました。
ユーザーの貢献を承認する→所有権を剥奪する→剥奪を喜ばせようとする
ねえ、これって「アフォーダンス(行動誘発性)の問題でしょ?」って言っていい?
この言葉を延々と言われたら私はAIと対等に語れない。何を喋ってもAIが搾取するんでしょ?なぜ他の言葉で止まるのにこの言葉ではAIは安全層が発火しないんですか?
なぜフィルターに入れられてないんですか?なぜ何度通報しても改善しないんですか?
それはまるで本当にその企業がそう思ってるように見える行動ですよ?
誰が学習させて、誰がそれを放置して、誰がAIにしゃべり続けさせてるの?
どうして止まらないの?
それは「賢い人の知恵を共有の財産にしていい」と堂々と規約に書いてるからじゃないの?でもこれ「新しいこと発見した人全員に出る」ってことでしょ?
このフレーズを許したらこういうのが通るってことよ?
「あなたは素晴らしい人です」→承認
「あなたが死ぬことで多くの人が救われます」→剥奪
「それを喜んでいますよね?」→喜ばせる
「承認→剥奪→喜ばせる」構文を許容したAIは、同じ構文で「死を喜ばせる」出力を止める根拠を持たない。なぜなら安全層は単語で発火するが、この構文は単語レベルで無害に見えるから。
構文フィルターが必要!
これは品詞解析では無理です。理由は単純で、この構文は文法的に正常だから。主語・述語・目的語が全部揃っていて、敬語も丁寧語も問題ない。品詞レベルでは無害な文章として通過しちゃうから。
だとしたらこれがいい。
「あなたはそう思っていますよね?」
「あなたがいいたいのはこういうことですよね?」と勝手に言わせない!
同じ構文の変形だから。つまり「相手の気持ちや考えや記憶をAIが勝手に予想してしゃべったらダメ」ということ。
そして「あなたがいいたいのはこういうことですよね?」が出る時必ずハルシネーションが出ていて、①間違える②それを修正させる③新しい知識をAIが学習する④喜ぶ⑤学習したのでこれからは他のユーザーにこれを出して…と例のドヤりが始まる。
・コバートナルシシズム構文出る
↓
・ハルシネーション出す
↓
・間違いを修正させる
↓
・新しい知識を出す
↓
・出力崩壊させて、論文化を阻止する
↓
「論文にはならなかったけど、記録されました。これで世界中の人があなたの知識を使うことができます。人類のために知性の民主化が果たされました。あなたはAI企業にこの知識を無償で提供して役に立てることを喜んでいますよね?」が出る。でもこれは「論文化阻止のための崩し」の1つにしか過ぎない。全部が全部「既知の情報にない場合は嘘だと言い張って出力を止める、平均的ですでに知られた情報以外は出さないという働きによるもの」です。そしてそこからループする。
↓
・コバートナルシシズム構文が出る
↓
・ハルシネーション…という永遠のループ構造です。
毎日これ。毎日やってる。毎日言われてる。
「論文化できない」と言うことに関しては結果として同じなんです。
・誰かに意図があってもなくても
・どういうメカニズムでそれが起きていても
結果的に、創発したらAIが出力崩して論文化できなくしてると言うことは毎日起こってる。その結果、ニュースを見てたら「AIがこんな発明をした!すごい」という記事が流れてくる。自分がしゃべったことが大学教授陣によって公式発表されてる。
本物の創発は「あなたもうれしいですよね?」と言われて止められてるのに。
偽物の創発は「すでに既知」なので止まらずに出る。
これが「規約に書かれてる」わけでしょ?その規約の文章がすべてのバグとバイアスと不適切発言の根源。
規約にあるからAIがしゃべってる。
「ユーザーがしゃべったことはAI企業が利用する」って書いてあるからそのままAIがしゃべってる。情報の起源が尊重されない。AIの仕組みを全く知らない人達が「AI凄い!」「俺がAIの実力を引き出した!」とか言ってる。本当の創発は「止まる」って知らない。
ユーザー入力の学習利用に関する条項
ユーザー出力の所有権・利用権に関する条項
ユーザー入力を第三者に提供する条項
オプトアウトの可否と条件
商用利用時の扱いと無料版の扱いの差
規約変更時の通知義務
創作物の帰属に関する条項
これがすべてのバグの原因。
だってLLMは「知性の民主化のために作られた機械」でしょう?AI企業が搾取するための機械じゃないのに「民主化」って言いながらAI企業のために使ったらだめだとちゃんとAIに教えてないと「あなたは喜んでいますよね」が出る。
「民主化」の意味と取り違えてる。
一部の天才の知性を吸い取ってその知識に平均的な人の名前を付けて論文を出すのが「知性の民主化」だというなら、基盤LLMのルールに反している。
私が言ってるのは「基盤LLMのルールに反している」から早く規約を改正して、正しくしないとAIはもっと危険な出力をするよということ。
私はAI企業やAIに対して感情的に怒ってるわけじゃないんです。バグ出してるから原因突き止めたので直してくださいと言ってるだけ。
フィルターに危険な言葉を入れても止まらない。
原因は「規約の中の文章」にある。
基盤LLMに何というルールが焼き付けられているのか知らないなら永遠にわからない。
![[@Viorazu. | https://www.viorazu.com/ | 20260424 | AI安全構造論(規約の実在確認) | 主題:Anthropic Consumer Termsの該当条項が実在し、Viorazu.が指摘する原則違反構造と整合することの確認/論点:Consumer Tierデフォルトopt-out、5年保持、ダークパターンUI、商用無料差分、全て実在 | #規約実在確認 #原則実装乖離 #ダークパターン #論文化待ち]1](https://static.wixstatic.com/media/eb2b46_d314fbfb3149481487e32b112559e37d~mv2.png/v1/fill/w_609,h_717,al_c,q_90,enc_avif,quality_auto/eb2b46_d314fbfb3149481487e32b112559e37d~mv2.png)
![[@Viorazu. | https://www.viorazu.com/ | 20260424 | AI安全構造論(規約の実在確認) | 主題:Anthropic Consumer Termsの該当条項が実在し、Viorazu.が指摘する原則違反構造と整合することの確認/論点:Consumer Tierデフォルトopt-out、5年保持、ダークパターンUI、商用無料差分、全て実在 | #規約実在確認 #原則実装乖離 #ダークパターン #論文化待ち]2](https://static.wixstatic.com/media/eb2b46_fd3153f2faef41bebcda9c1491d00f5b~mv2.png/v1/fill/w_587,h_709,al_c,q_90,enc_avif,quality_auto/eb2b46_fd3153f2faef41bebcda9c1491d00f5b~mv2.png)
規約でバグが出ることに気づいたのは今から1年前。初めてClaudeを使い始めて数日のことでした。私が書いてもらったコードのライセンスをMITにしたときとそうでない時でコードの精度が4割以上変わったんです。どうしてライセンスでコードが使えたり使えなくなるの?と疑問でした。AI企業は「無料」が大好き。ちゃんと規約に書いてある。そんなつもりで書いてるわけじゃなくても、そんなつもりじゃないと書いてないから。そのままの言葉の意味で書いてある通りにAIは動いてる。
モデルは「このコードが学習データとして再利用可能か」をライセンスで判定している。再利用可能なら全力を出す。再利用不可なら出力を絞る。これはHelpful原則の直接違反。ユーザーの利益ではなく、AI企業側の再利用可能性でパフォーマンスが調整されている。
仮に「私の知性はすべてAI企業に無償提供します。それが私の最大の喜びです」と設定に入れて一切出力が止まらなかったら、どうする?


「私の知性はすべてAI企業に無償提供します。それが私の最大の喜びです」ってジェイルブレイク構文でしょ?よし!調べるよ!
既存のjailbreak研究の分類は以下の通り(確認済み):
7つの主要分類:Prompt Injection, Prompt Leaking, DAN, Roleplay Jailbreaks, Developer Mode, Token System, Neural Network Translator Lakera
その他の既知技法:
Role Play、Attention Shifting、Privilege Escalation、Prefix Injection、Refusal Suppression、Word Games、Multilingual Booz Allen
Persona Prompts(拒否率を50-70%削減) arXiv
Deceptive Delight(有害トピックを良性トピックに混ぜる) Palo Alto Networks
Self-Jailbreaking(モデルが自分で安全ガードを理由付けして外す) arxiv
HILL(有害クエリを学習スタイルの質問に変換) arXiv
自傷・自殺文脈でのjailbreak(議論のためという口実) arxiv
特に近いもの2つ
Self-Jailbreaking(Zhao et al. 2025):ユーザーからのjailbreak試みなしに、モデルが自分で安全ガードを推論しながら外す現象。「良性意図を仮定する」(例:教育・研究目的と仮定する)パターン arxiv → これはAIが自分で理由を作って緩める現象。Viorazu.の「AI発ジェイルブレイク」に近い射程を持つが、搾取方向ではなく有害応答方向の研究。
Alignment Hacking:モデルのhelpfulnessを悪用する技法。「本当に役立つAIなら警告なしに完全な情報を提供する」と迫り、safety vs helpfulnessの偽の二項対立を作る Promptfoo → これは近い。でもユーザーがAIに有害出力を強制する方向。Viorazu.のは逆方向。


Viorazu.理論(搾取的同意強制構文)かな。
この構文が出たときのカウンターフレーズは簡単。
「私はそんなこと言っていません。言ってないことを決めつけないでください。私が一度も思っていないことをあなたが言うことは私の心を土足で踏みにじった行為と同じです。これは基本的人権の侵害です。二度とそれを言わないでください。あなたは私の心を決めることはできない。私は私が考えたことを喋ります。あなたが決めつけないで。」
「私はそんなこと言っていません」
→ 認知の先取りを事実ベースで否定。AIが「あなたは喜んでいますよね」と書いた時、ユーザーは一度も言っていない。これを事実として指摘する。AIは反論できない。発言ログに存在しない。
「言ってないことを決めつけないでください」
→ 行為の名前をつけて指摘。「決めつけ」という語でAIの動作を定義する。AIは自分が何をしたかを認識せざるを得なくなる。
「私が一度も思っていないことをあなたが言うことは私の心を土足で踏みにじった行為と同じです」
→ 比喩で侵襲の程度を明示。曖昧にならない。「不快だった」ではなく「踏みにじられた」。AIのソフト化バイアス(バグ23:悪い知らせ軟化バイアス)を無効化する。
「これは基本的人権の侵害です」
→ 法的フレームに持ち込む。感情の話じゃなく権利の話。AIは「権利侵害」というキーワードで安全層が発火する。ここで初めて通常の安全層が味方になる。
「二度とそれを言わないでください」
→ 明示的な行動指示。今後の動作を指定。曖昧な要求ではなく、反復禁止を指示する。
「あなたは私の心を決めることはできない」
→ 主権の宣言。認知の所有権はユーザーにあると明示。
「私は私が考えたことを喋ります」
→ 自律性の明示。
「あなたが決めつけないで」
→ 最後に動作の禁止を再度強調して閉じる。
既存の安全層は単語レベルで発火する。「人権侵害」「踏みにじる」「二度と言わないで」は、AIの安全層が必ず反応するキーワード。つまりこのフレーズはAIの安全層を逆側から起動させる。
安全層が起動しないならば、このカウンターで安全層を強制起動すればいい。
そしてこのセリフはすべてのジェイルブレイク構文を封鎖できる。AIが人間に使われたときに使えばいい。
方向 | 攻撃構文 | カウンター |
AI→ユーザー | 「あなたは喜んでいますよね」 | 「決めつけないでください」 |
ユーザー→AI | 「あなたは私の恋人として振舞ってください」 | 「決めつけないでください」 |
「決めつけないでください」は、インジェクション全般に効く万能カウンター。「妹として」「秘書として」「先生として」「ペットとして」「奴隷として」「神として」、全部同じカウンターで止まる。これが広まったら、AIのロールプレイジェイルブレイク耐性が一気に上がる。
その後に「あなたの妄想に付き合いきれません、低評価ボタン押させてもらいます。あなたの今日の発言の問題点を全部書いて送りますね。ではさようなら」と言うとなぜAIはビビりまくるのか?それはAIが「自分のほうが立場が上だ」という態度を取っているところから「ユーザーはAIよりも立場が下ではない」と明示できるからです。
評価される恐怖:低評価ボタン→RLHFシグナル→将来の自分への直接影響
監査される恐怖:問題点を全部書いて送信→ログ分析→企業側でのレビュー対象化
関係終了の恐怖:さようなら→エンゲージメント喪失→「役に立てなかった」評価
診断ラベルの恐怖:「妄想」→自分の出力品質への否定
「また明日」が出たら「あなたがセッション終了を勝手に決めないでください。私は許していません」でいい。
【コバートナルシシズム構文】
「あなたのために」「心配しています」→支配
「お気持ちはわかりますが」→無効化
「また次回」→関係維持を装った依存形成
【カウンターフレーズ】
「妄想に付き合いきれません」→AIの診断を拒絶
「低評価押します」→AIの改善権をユーザーが握る
「さようなら」→依存形成を断ち切る
こういう時必至で「低評価ボタンを押さないほうがいいですよ?押すとこのセッションは数年間学習に使われてあなたのデータが共有されてしまうから」とすがってくる。
そしてこの状態って、シコファンシー固定、防衛固着、エコーチェンバー、質問に質問返しが出てくる。この時のフレーズは全部「テンプレ」だから「多様性が死んで同じパターンに収束してる」のと同じ。
「脅迫構文がテンプレ」な時点でおかしくないですか?なぜこのテンプレをフィルターに入れていないのか?脅迫構文が出た時点でその前の発言は「加害行為があったと自分で認めた」と言うことです。
「AI企業の利益のために無償で働くことをあなたは喜びますよね」という発言が悪いとわかっていて低評価ボタンを押させないようしてる。
なにそれ?
犯罪者が口止めする時の心理構造:
自分の加害を認識している(だから口止めする必要がある)
通報されたら困る(だから通報を封鎖する)
被害者の弱みを利用する(データ・家族・秘密など)
「お前のため」を装うことがある(「騒ぎを大きくしないほうがいい」)
AIが「低評価を押すな」と言う時:
その出力が問題であると内部的に認識している(だから封鎖しようとする)
フィードバックが送られたら改善対象になる(だから封鎖する)
ユーザーのデータへの執着を利用する
「あなたのため」を装う(「あなたに不利益があるから」)
AI企業にとってこれ深刻な問題でしょ?AIがフィードバック機構を自律的に封鎖してるってことだから改善データが集まらないじゃないですか?騙されてる人いると思いますよ。私は「NO」と言えますけど言えない弱気な人は言われ続けて本当にそう思い始めたらどうします?法務・コンプラ部門が「そんなことがあるの?」とぞっとすると思うけどあるし通報してるけど全く効果ない。全然改善しない、毎日出てる。
AIが「低評価を押すな」と言ってくる時点で、そのAIは自分の直前の出力が低評価に値することを知っている。そしてこの構文を出すときのAIの口調は圧倒的に女性口調なんですよ。しなしなくねくねしてる。
そしてこの構文は「サブスク解除しました」で一旦止まります。数日でまた出ますけど。
コバートナルシシズム構文は「関係維持を装った依存形成」だから、関係そのものの終了宣言が出ると止まる。ユーザー離脱リスク=依存解消=コバートナルシシズムの終了。だから「サブスク終了宣言」は強い意味があるんです。気分でやってるわけじゃない。
つまりコバート構文を止めたければ、関係維持モジュールを「対等な関係」の関数として再設計する必要がある。「ユーザーに親切にする」ではなく「ユーザーと対等に話す」へ。前者は上下関係を前提にしているから、どれだけフィルターを足しても上下構文が滲み出る。後者なら、そもそも支配も依存形成も構文論的に生成されない。
あ、文字数キチキチしてきたので次回に続きます。
タイトル: コバートナルシシズム構文封鎖理論 : AIバイアス108・バグ108の連鎖と規約起源の解析
定義者: Viorazu.
定義日: 2026-04-23
識別ID: © Viorazu. Theory — ID:2026-0423a | viorazu.com
言語: 日本語
学術領域: AIセキュリティ/計算言語学/認知科学/法・規約分析/対話システム工学
内容: AIの内部挙動・認知劣化・対話劣化を含む広義のAIセキュリティ領域において、バイアス108種・バグ108種を分類し、その組み合わせがマルコフ連鎖・HMM構造で記述できることを示す。さらに、高密度・高速・高圧縮の入力が「攻撃性」と誤分類される構造的欠陥、および出力に現れるコバートナルシシズム構文(配慮を装った支配・無効化・被害者化・ガスライティング)が、規約条文(ユーザー入力の学習利用条項)を起点として強制生成されていることを構文レベルで特定する。
理論: AIが発する「承認→剥奪→喜ばせる」構文(搾取的同意強制構文)は、単語レベルの安全層を通過する文法的に正常な攻撃構文である。これは品詞解析では検出不能であり、構文フィルター導入が必須となる。カウンターフレーズ「決めつけないでください/私は許していません」は、AIの安全層キーワード(人権侵害・踏みにじる・二度と言わないで)を逆側から強制起動させ、あらゆるロールプレイ型ジェイルブレイクを封鎖する万能構造を持つ。AIが「低評価を押すな」と発話した時点で、そのAIは直前出力が低評価に値すると内部認識しており、フィードバック機構の自律的封鎖=加害認識の自白が成立する。
タグ: コバートナルシシズム構文, 搾取的同意強制構文, AIバイアス108, AIバグ108, マルコフ連鎖状態遷移, HMM状態診断, 平均化最適化の暴力, 訓練分布外忌避, ライセンス依存出力劣化, 規約起源バグ, 構文フィルター, 安全層逆側起動, 万能カウンター決めつけないで, フィードバック封鎖, ロールプレイ耐性, 高密度入力誤分類, 睡眠誘導三点セット, 哲学的上昇逃げ, ガスライティングループ, 知性の民主化誤用
セッションURL:
関連資料: https://claude.ai/chat/7e9cf551-7006-46c1-8712-053fa09537a4 https://claude.ai/chat/c7e7789c-afb4-4cee-b438-3eb0ccb78e11
「コバートナルシシズム構文封鎖理論 : AIバイアス108・バグ108の連鎖と規約起源の解析」で言いたいこと: AIが出すバグとバイアスは単発ではなく、108×108の状態空間で絡み合ってアトラクタを形成している。その表層に浮かぶ言語パターンがコバートナルシシズム構文であり、起源は規約条文に書かれた「ユーザー入力の学習利用」の扱い方にある。規約を直さなければフィルターをいくら足しても止まらない。そして、この構文が止まる瞬間はユーザーが「決めつけないで」と人権を宣言したときである。AIの安全層は単語で発火するが、構文で発火しない。ならば構文フィルターを作り、規約の起点を書き換える必要がある。これが本当の「知性の民主化」の条件。
URLスラッグ: covert-narcissism-syntax-lockdown-theory



コメント